TL;DR
Téléchargements • Nouveautés
Le dictionnaire français original de la Kobo ne casse pas trois pattes à un canard. Il est pauvre en définitions.
J'ai tenté ma chance avec le Littré, il y avait du mieux. Cependant, une bonne partie des définitions ne m'aidait pas du tout (un peu vieux [1863], trop verbeux, trop de latin, pas assez d'explications claires et l'affichage peu agréable).
Donc, l'idée, c'est de générer un dictionnaire aux normes en utilisant la volumineuse base ouverte de connaissances du Wiktionnaire.
Le Projet
Les sources du projet se trouvent sur GitHub : eBook Reader Dictionaries.
Tout est automatisé : le rapatriement des définitions et la conversion au bon format.
Si vous souhaitez rentrer dans les détails, c'est du code Python couplé à des Actions GitHub.
Le dictionnaire est automatiquement mis à jour tous les jours, à minuit. Nous avons donc là un dictionnaire qui évoluera avec le temps, et si un mot est manquant ou sa définition vague/erronée, il n'y aura qu'à apporter les modifications sur Wiktionnaire directement, et au prochain export de leur base de données, la nouvelle version du dictionnaire contiendra la définition du mot. Je trouve ça génial, pas vous ? ☻
Mais ce n'est pas tout, voici quelques fonctionnalités exclusives :
- Lors de la sélection d’un mot au pluriel, sa forme au singulier sera affichée.
- Lors de la sélection d’un verbe conjugué, sa forme à l’infinitif sera affichée. → dusse
- Si un mot au pluriel redirige vers plusieurs autres mots (un nom au singuler, un ou plusieurs verbes, ...), les différents mots seront affichés. → grognasses
- Si un mot contient plusieurs prononciations, elles seront toutes affichées. → greffier
- Les formules mathématiques sont transformées en images vectorielles pour être parfaitement lisibles. → cercle unité
- Les formules chimiques sont transformées en images vectorielles pour être parfaitement lisibles. → porphobilinogène
- La prise en charge des hiéroglyphes. → gomme
- La prise en charge des tableaux. → -eresse
Voici les liens de téléchargement du dictionnaire :
L'installation est relativement simple : copiez le fichier tel quel dans le dossier .kobo/custom-dict de votre liseuse (ou .kobo/dict si vous utilisez un firmware < 4.24).
Comparaisons
À titre informatif, voici un tableau récapitualtif, assez parlant, des dictionnaires français :
| Dictionnaire | Nombre de mots | Poids du fichier |
| Robert Micro 2013 | 31 593 | 3,7 Mio |
| Littré | 78 000 | 39,7 Mio |
| Wiktionnaire (ce projet) * | 1 862 030 | 36,5 Mio |
* Données au 2023-09-24, les informations sont très certainement périmées étant donné que le dictionnaire est en constante évolution.
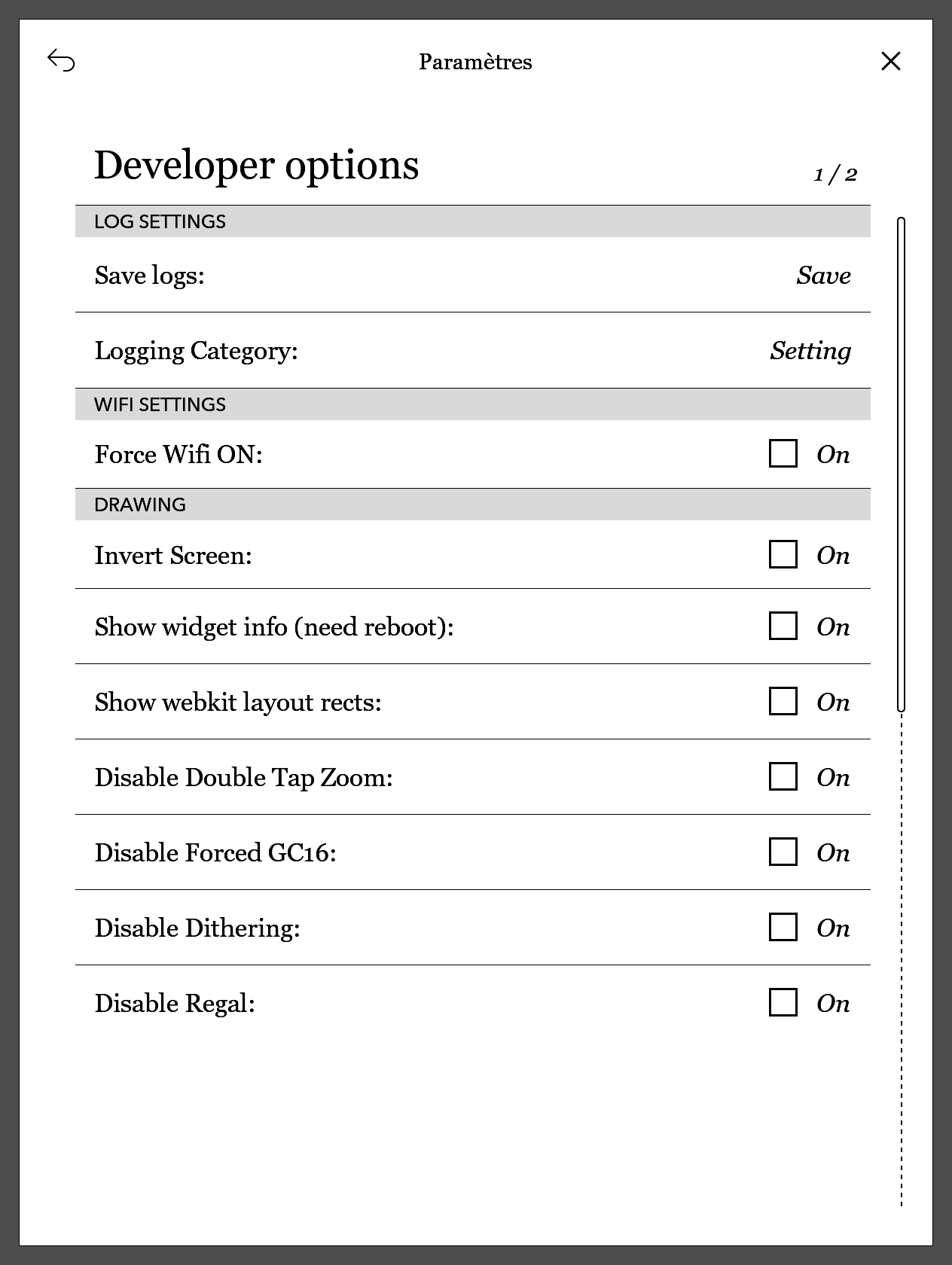
Détails Techniques
Pour ceux et celles qui ont envie d'en apprendre plus sur le format du dictionnaire de la Kobo, vous pouvez continuer à lire.
La Recherche de Mots par Kobo
En récupérant les logs de la Kobo, on peut avoir un début de compréhension du bousin.
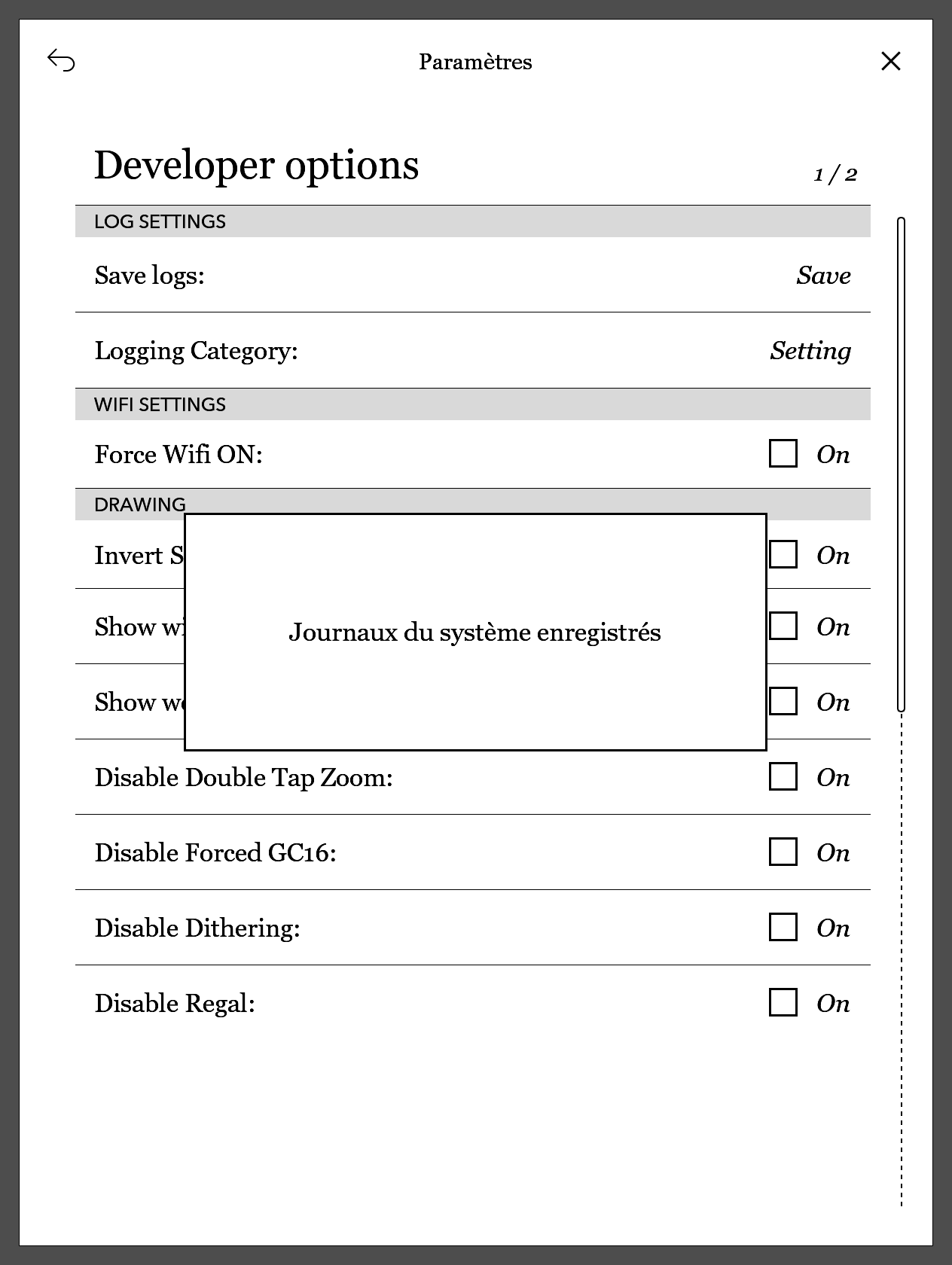
Par exemple, pour un mot qui ne se trouve pas dans le dictionnaire, ces lignes seront enregistrées (ivroïde) :
Apr 17 20:18:31 nickel: ( 2657.645 @ 0x1e912f0 / dictionary.debug) got alternative search terms: ("ivroïde", "IVROÏDE", "Ivroïde") for word: "ivroïde"
Apr 17 20:18:31 nickel: ( 2657.646 @ 0x1e912f0 / dictionary.debug) word: ""
Et pour un mot figurant dans le dictionnaire (eidétique) :
Apr 17 20:22:43 nickel: ( 2871.288 @ 0x1e912f0 / dictionary.debug) got alternative search terms: ("eidétique", "EIDÉTIQUE", "Eidétique") for word: "eidétique"
Apr 17 20:22:43 nickel: ( 2871.289 @ 0x1e912f0 / dictionary.debug) word: "eidétique"
Apr 17 20:22:43 nickel: ( 2871.289 @ 0x1e912f0 / ui.debug) static QByteArray Unzipper::extractFile(const QString&, const QString&) "/mnt/onboard/.kobo/dict/dicthtml-fr.zip" "ei.html"
C'est bien joué de la part de Kobo d'avoir ajouté ces informations de debogage. Nous venons d'apprendre que lorsqu'une recherche d'un mot est initiée, ses équivalents en lettres capitales et "titre" sont recherchées en même temps. Deux choses :
- Ça évite d'avoir à se prendre la tête pour les mots : autant ne générer que des mots en minuscules.
- Ça permet de récupérer plusieurs définitions : si le même mot existe dans le dictionnaire en minuscule et "titre", alors les 2 mots seront affichés (par exemple).
Nous venons aussi d'apprendre que, quand un mot existe dans le dictionnaire, sa définition est récupérée depuis le fichier
${lettre1}${lettre2}.html compressé dans dicthtml-fr.zip.Format du Fichier ZIP
Le fichier ZIP doit se nommer dicthtml-$LOCALE.zip et se trouver dans le dossier .kobo/dict.
Ce ZIP contient plusieurs fichiers HTML et un fichier spécial words :
$ unzip -l dicthtml-fr.zip
Archive: dicthtml-fr.zip
Length Date Time Name
--------- ---------- ----- ----
100 2020-04-18 14:31 11.html
399 2020-04-18 14:31 ac.html
205 2020-04-18 14:31 au.html
280 2020-04-18 14:31 ba.html
275 2020-04-18 14:31 em.html
145 2020-04-18 14:31 ic.html
193 2020-04-18 14:31 l’.html
250 2020-04-18 14:31 mo.html
294 2020-04-18 14:31 pi.html
333 2020-04-18 14:31 qu.html
170 2020-04-18 14:31 sl.html
238 2020-04-18 14:31 œc.html
4192 2020-04-18 14:31 words
--------- -------
7074 13 files
Format des Fichiers HTML
Chaque fichier HTML se nomme suivant la 1ère lettre et la 2ème lettre des mots qu'il contient.
Pour les nombres, les symboles et certains caractères unicode, il sont placés dans le fichier fourre-tout 11.html.
Bien que les fichiers ont l'extension .html, il s'agit en fait de données compressées à l'aide de gzip.
Une fois décompressés, nous avons enfin un fichier HTML.
Voici le format d'un fichier HTML décompressé (la première ligne est optionnelle) :
<?xml version="1.0" encoding="utf-8"?>
<html>
<w>mot</w>
<w>mot</w>
...
</html>
Où "mot" est du code HTML. Là, il n'y a pas vraiment de restrictions, chacun fait sa propre sauce. Et c'est pourquoi Le Littré a parfois un rendu trop compact.
Pour information, le Robert Micro 2013 utilise ce format HTML :
<p>
<a name="mot"/>
<b>mot</b> [prononciation] <i><b>genre</i></b>
<br/>
<ol>
<li>Définition 1</li>
<i>Citation</i>
</ol>
</p>
→ [fondation]
Le Littré utilise ce format :
<a name="MOT"/>
<div>
<b>MOT</b>
<br/>
<i><small>(prononciation) genre</small></i>
Définition 1. Définition 2.
<big>ÉTYMOLOGIE</big>
Étymologie.
</div>
→ [fondation]
Et enfin, Wiktionnaire (ce projet) utilise ce format :
<p>
<a name="mot"/>
<b>mot</b> prononciation <i>genre</i>
<br/>
<br/>
Étymologie.
<ol>
<li>Définition 1.</li>
<li>Définition 2.</li>
</ol>
</p>
En réalité, j'altère ce code pour y inclure le nom du dictionnaire, voyez Hack pour modifier le nom du dictionnaire pour plus d'informations.
→ [fondation](aperçu au 2020-09-27, l'affichage a pu avoir changé depuis)
Format du Fichier Spécial
Il reste le petit dernier : words.
Quelques informations peuvent être glanées :
$ file words
words: data
$ head -c 15 words
We love Marisa.
Après quelques recherches, et grâce au code source de Penelope, j'ai compris qu'il s'agissait d'un trie (ou arbre préfixe). L'article sur Wikipédia explique plutôt bien le principe, je ne tenterai rien de ce côté-là.
Par contre, cela nous permet de comprendre les logs de la Kobo. Ce fichier est chargé en mémoire et lorsqu'une recherche est initiée, l'application peut rechercher rapidement si la définition existe dans un des fichiers HTML. Si c'est le cas, le fichier est extrait du ZIP, décompressé en mémoire et la définition est parsée.
Ce qui explique que, même avec des dictionnaires plus lourds que l'original, le processus reste efficient : aucune attente supplémentaire n'est ressentie.
Autres sources :
Historique
- 2023-09-24 : mise à jour du tableau récapitulatif (1 833 278 → 1 862 030 mots, 35,6 → 36,5 Mio).
- 2023-03-25 : ajout du dictionnaire roumain.
- 2023-01-26 : ajout des captures d'écran pour la formule chimique et les hiéroglyphes, utilisation des liens de téléchargement traduits et comportant plus d'informations quant aux fichiers disponibles, et mise à jour du tableau récapitulatif (1 804 462 → 1 833 278 mots, 34,4 → 35,6 Mio).
- 2022-05-11 : ajout du dictionnaire russe et mise à jour du tableau récapitulatif (1 794 375 → 1 804 462 mots, 34 → 34,4 Mio).
- 2022-01-28 : ajout du dictionnaire allemand et mise à jour du tableau récapitulatif (1 589 612 → 1 794 375 mots, 32.3 → 34 Mio).
- 2022-01-27 : adaptation du nom des dictionnaires (dicthtml-fr.zip → dicthtml-fr-fr.zip).
- 2021-08-23 : ajout de la capture d'écran pour les tableaux et mise à jour du tableau récapitulatif (1 581 440 → 1 589 612 mots, 32,1 → 32,3 Mio).
- 2021-07-04 : ajout du dictionnaire grec et mise à jour du tableau récapitulatif (1 575 287 → 1 581 440 mots, 31,9 → 32,1 Mio).
- 2021-05-13 : ajout des dictionnaires italien et norvégien, mise à jour du tableau récapitulatif (1 532 068 → 1 575 287 mots, 28,5 → 31,9 Mio).
- 2020-12-12 : suppression de l'affichage des images d'aperçus, il s'agit de simples liens maintenant.
- 2020-12-03 : suppression de la section "Autres formats", trop problématique.
- 2020-11-16 : ajout des captures d'écran pour les fonctionnalités exclusives.
- 2020-11-12 : ajout des fonctionnalités exclusives, de la liste complète des langues supportées et mise à jour du tableau récapitulatif.
- 2020-09-27 : mise à jour du tableau récapitulatif et de la capture d'écran.
- 2020-08-13 : ajout de la section Autres Formats.
- 2020-05-20 : mise à jour du tableau récapitulatif, des captures d'écran et des liens vers les langues disponibles.
- 2020-05-04 : mise à jour du tableau récapitulatif, des captures d'écran et du code HTML pour les mots de ce projet.
- 2020-05-01 : mise à jour du tableau récapitulatif et de la capture d'écran.
- 2020-04-24 : ajout des captures d'écran.













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}